2 weeks ago, Mark Zuckerberg revealed the Meta Ray-Ban vision during the Meta Connect. People classify this product at the same technological level as VR and AR, taking the example of the Vision Pro, or more similarly the Google Glasses, both huge flops.
But the Meta glasses have a plus.
AI.
And I think that if Meta Glasses surely need AI, AI needs Meta glasses.
“I use Chat GPT as a general purpose tool, and I hope that in a few years I will use it in more things than I do. It’s obviously still terribly integrated into most people’s workflows, but it’s going to get better at that.”
For anyone that has tried to build anything serious with AI, you quickly find that the tech is not the real challenge, it’s how you implement it in the user routine and how you make it easy for the user to fill their context.
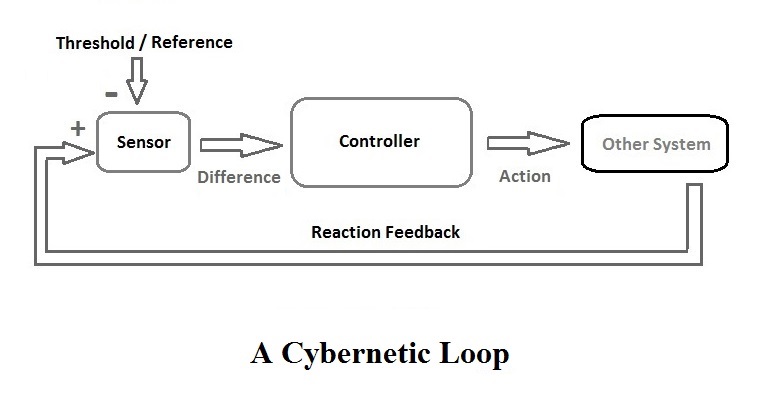
This is why the best AI apps are wired to email and calendar. And this concept is nothing without AI capacity to analyze the result of its predictions. It’s called the cybernetic feedback loop: AI prediction → positive or negative feedback → re-adjustment of the next prediction toward a positive feedback. It is the base concept of what Bryan Johnson does with his project Don’t Die: every day he varies his daily routine and monitors his sleep quality and then maximizes the element that reinforces his sleep quality and minimizes what weakens it.
Principle diagram of a cybernetic system with a feedback loop
This capacity for AI to reach its feedback is very easy in mathematics, video games, and programming, where everything happens in a very simple virtual and closed environment. This is why all the exponential growth of AI currently only happens in these fields.
If you want to expends the exponential to other field you need live visual and audio context. You need a new, AI first device. This is why both Mark Zuckerberg and Sam Altman, with its collaboration with Jony Ive, are after it.
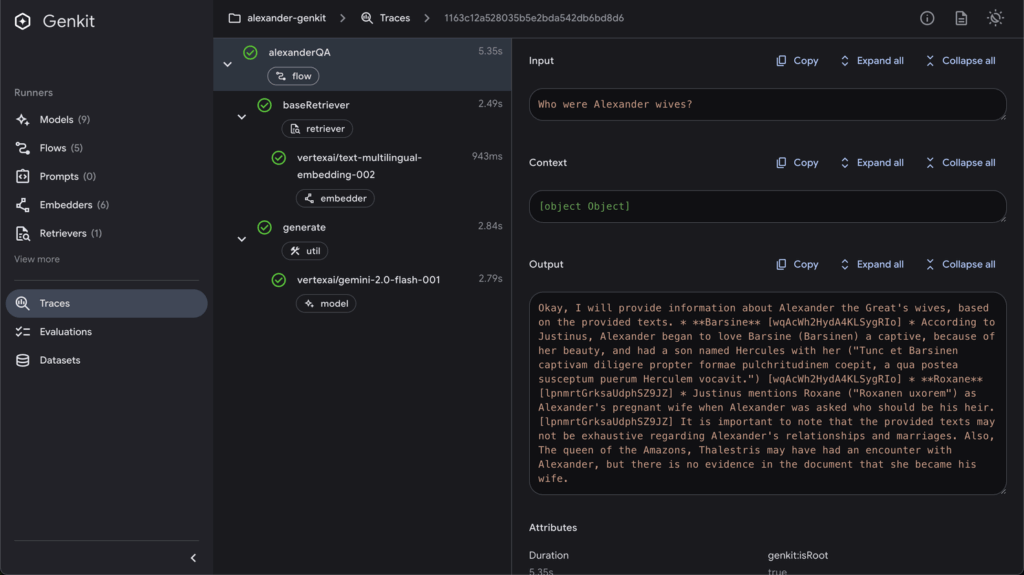
By creating my Alexander the Great, an app running on ancient Greek books, people really underestimate how hard it is to insert even an incredible app into their daily life, for 2 reasons: it needs to be somehow ritualistic, and you have no idea how it could help. It’s why top apps are fitness apps (ritualistic) and general purpose AI apps (whatever you ask, you will always have a reply).
I built a mobile application focused on Ancient Greek texts, polished it to perfection, and released it on the app store. Despite its genuine usefulness, I found zero audience. What I didn’t realize was that I had stumbled into a $270 million problem—and potentially, its solution.
The Personal Journey That Started It All
A few years ago, when my son was born, I found myself carefully selecting stories to share with him. I wanted tales that would not only entertain but also teach him about life, character, and wisdom. This quest led me to fall in love with classical education.
There was one problem: I wasn’t a classical scholar, just a programmer. Leveraging tech to get my access to all these ancient text felt like the perfect move. I gathered all the ancient Greek texts about Alexander the Great and built them into an application I called “The Greatest Alexander the Great Application.”
The result exceeded my expectations:
More accurate than Wikipedia
Providing valuable advice for most life questions
Consistently delivering actionable insights every time I used it
Yet despite creating something genuinely valuable, I faced a harsh reality: zero audience.
The Hidden $270 Million Market
My failure led me to a surprising discovery. I wasn’t alone in this struggle: I had unknowingly entered the classical education market, worth $270 million in the US alone.
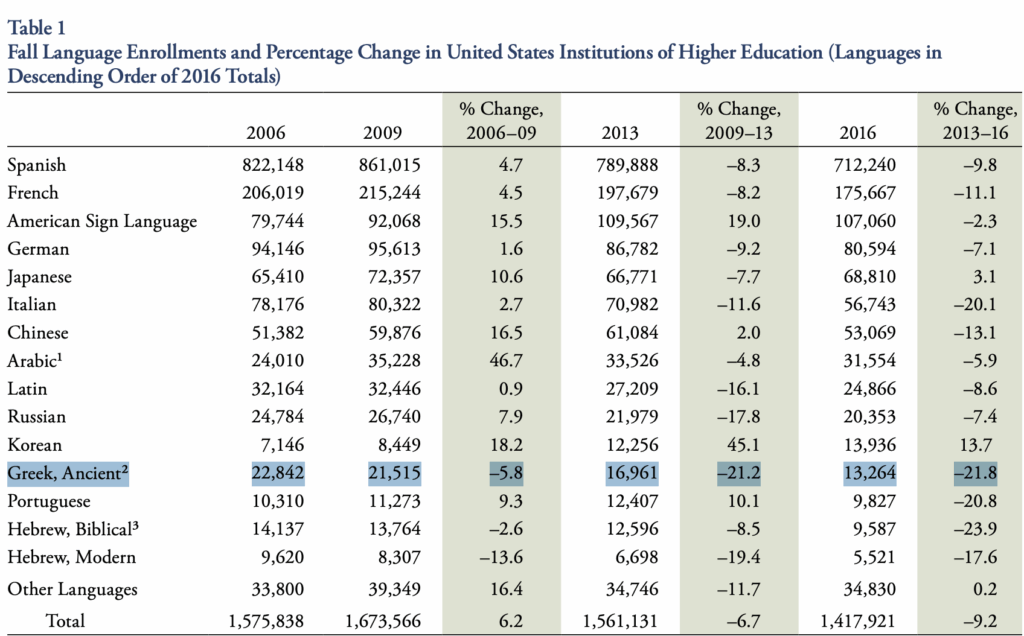
Source: Based on 677,500 students enrolled in classical education (2023-24, Arcadia Education market analysis) × estimated $400 per student spending on specialized curriculum materials
But this market faces a critical challenge: it’s shrinking fast. Ancient Greek enrollment dropped from 22,000 US students in 2006 to just 13,000 in 2016—a 40% decline in a single decade.
Many educators point to gamification as the solution. The theory sounds compelling: make learning fun through games, and engagement will follow.
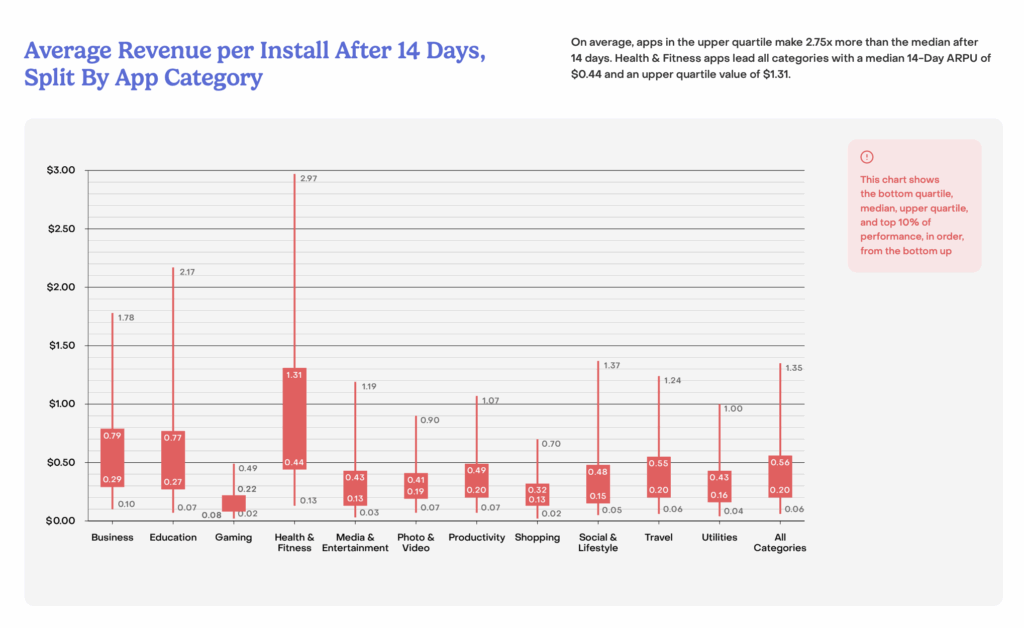
Revenue Cat, State of subscriptions 2025
But the data tells a different story. According to RevenueCat’s 2025 report, video games generate the lowest per-install revenue of any app category. Despite 15 years of hype around educational gaming, there are virtually zero examples of successful commercial educational games.
Meanwhile, on the other side of the spectrum, we see genuine success stories like Alpha School in Austin and Ad Astra (SpaceX’s private school)—both traditional, high-quality educational institutions that people pay premium prices to attend.
The Commercial Validation Principle
“If a product is World Class… it is a product, and somebody commercial has bought this product. It is very implausible that you will have the best software product in the world, and you never sold it commercially.”
– Alex Karp, CEO of Palantir
If I can’t convince people to pay for my solution, how can I be certain it actually solves their problem? The path forward isn’t to become the “Zynga of Classical Education” but rather to build something that combines the AI capabilities of a Grok with the practical wisdom and social media approach of a Ryan Holiday.
The Rebrand: From Alexander to Aristotle
I’ve begun transforming my Alexander the Great app into an “Ancient Coaching” application—essentially a virtual Aristotle. This better captures the app’s true purpose: providing personalized wisdom and guidance drawn from classical sources.
My strategy leverages several key elements:
Platform Focus: iOS as the primary platform, the US App Store being 70% share of all the mobile revenue.
AI Integration: The RAG (Retrieval-Augmented Generation) system I developed works remarkably well, providing contextually relevant advice from classical sources
Rewards: Creating a cybernetic feedback loop where the more someone uses the app, the more equipped they become to share its value with others
Future Technology: Preparing for emerging platforms like Meta’s Ray-Ban smart glasses, which could seamlessly integrate classical wisdom into daily life flow. No ned to fill manually the prompt context anymore (Just imagine getting Aristotle live as rehtorics advisor during an interview).
The Vision: Capturing Aristotle’s Worldview
“My hope is someday, we can capture the underlying worldview of that Aristotle in a computer and someday, some student will be able to ask Aristotle a question and get an answer.”
– Steve Jobs
That future is closer than we think. With current AI capabilities and the vast corpus of classical texts available, we can begin to approximate that experience today.
What’s Next
My journey is just beginning. With the Android version live and the iOS version in development, I’m building not just an app but a new category: AI-powered classical education that people actually want to use—and pay for.
The decline in classical education isn’t inevitable. It’s a market opportunity waiting for the right approach: one that combines ancient wisdom with modern technology, practical value with commercial viability.
The question isn’t whether there’s demand for classical wisdom—it’s whether we can package and deliver it in a way that fits into modern life. I believe the answer lies in AI, and I’m committed to proving it.
Follow my journey as I build the future of classical education. The next post will dive deep into the technical architecture of creating a virtual Aristotle and the early user feedback that’s shaping the product. You can follow me on X.com and Linkedin.
Google Gemini’s image editing feature threatened Photoshop before getting overshadowed by this open-source model. I’m telling you all about Flux Kontext, where to get it, and what prompts I use.
I’ve become addicted to Flux Kontext. Flux is a family of generative flow-matching models that can generate new images from text prompts and edit existing images, developed by Black Forest Labs, based in Freiburg, Germany. Their model was used by X for its image generation feature.
What makes Flux Kontext revolutionary is its capacity to edit and merge existing images very quickly. It’s the perfect model not only for professional image manipulation and restoration, but also for indie app developers like myself.
Here are the important things I learned from my experiments with the model:
Strengths:
Amazing at editing images (changing colorimetry, contrast, adding elements or backgrounds to paintings, restoring black and white photos, and copying styles)
Perfect for image restoration, like enhancing photos that were too dark
Can add or alter elements of pictures without changing their style, including backgrounds
Limitations:
Struggles with complex Renaissance paintings due to too many details
Cannot complete missing parts of pictures – for example, it wasn’t able to generate missing parts of paintings or mosaics. However, it can have some amazing results, like I experienced with the Pompeii Alexander Mosaic, especially from the Darius III side
Sometimes it just doesn’t work and you don’t know why
Where to Use It
It’s fully available on Replicate. You need to create an account on Replicate.com, enter your credit card information, and go to the model page at https://replicate.com/black-forest-labs/flux-kontext-pro, or you can use the model via API. Each run costs about $0.04 per image for 5-4 seconds of generation.
Example Prompts
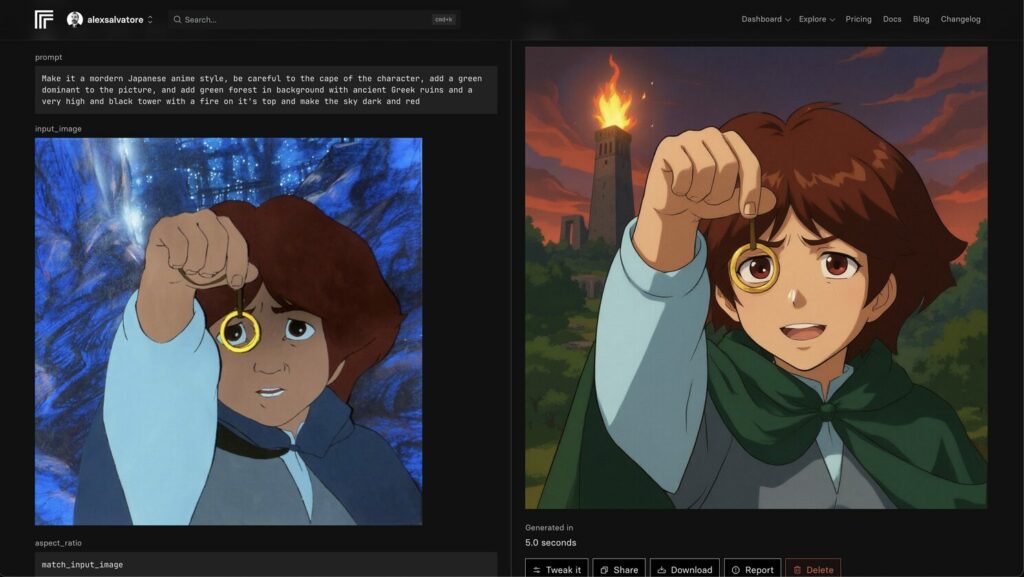
Prompt:Make it a modern Japanese anime style, be careful with the cape of the character, add a green dominant color to the picture, and add a green forest in the background with ancient Greek ruins and a very tall black tower with fire on its top, and make the sky dark and red
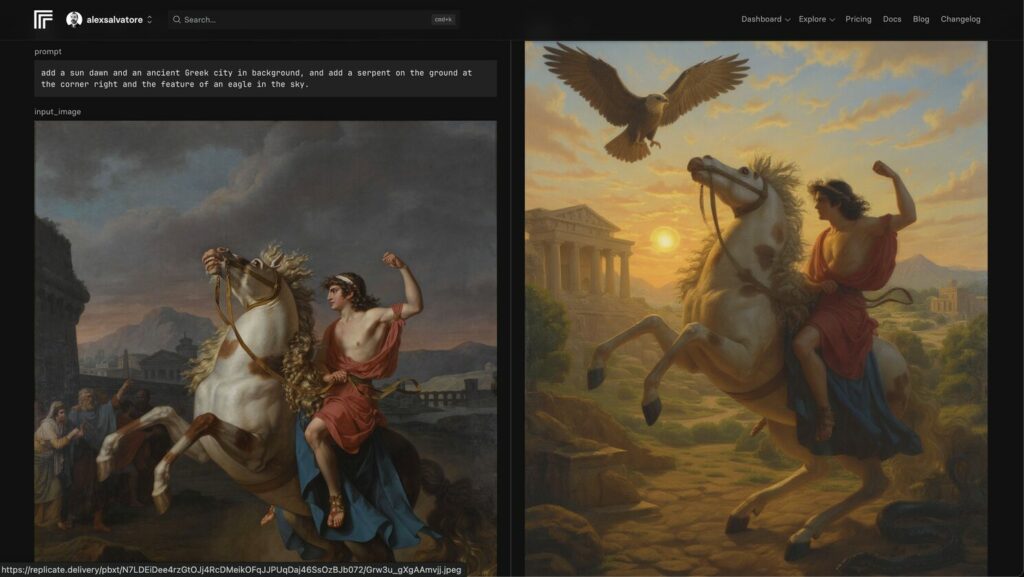
Prompt:Add a sunrise and an ancient Greek city in the background, and add a serpent on the ground in the right corner and the silhouette of an eagle in the sky.
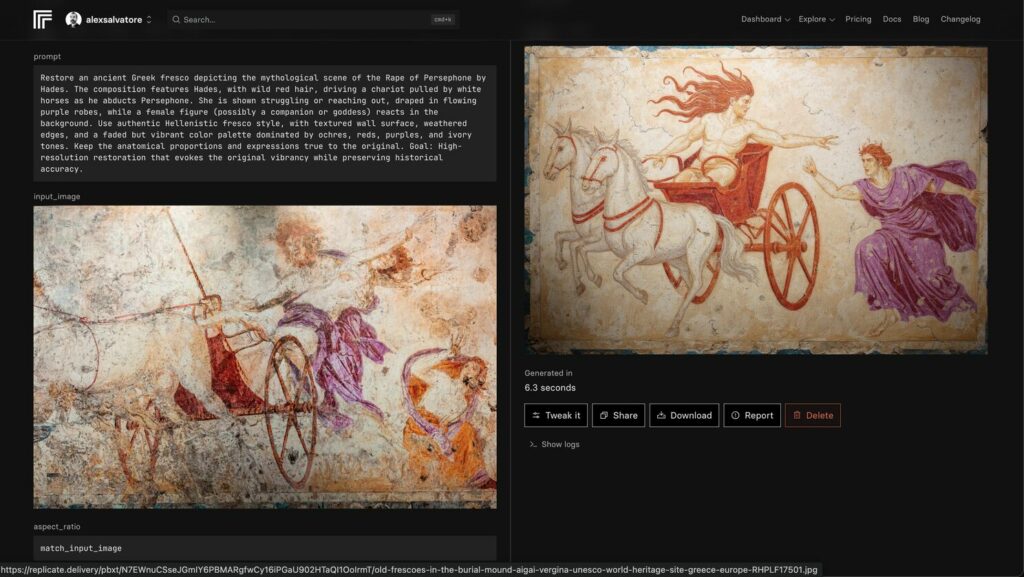
Prompt:Restore an ancient Greek fresco depicting the mythological scene of the Rape of Persephone by Hades. The composition features Hades, with wild red hair, driving a chariot pulled by white horses as he abducts Persephone. She is shown struggling or reaching out, draped in flowing purple robes, while a female figure (possibly a companion or goddess) reacts in the background. Use authentic Hellenistic fresco style, with textured wall surface, weathered edges, and a faded but vibrant color palette dominated by ochres, reds, purples, and ivory tones. Keep the anatomical proportions and expressions true to the original. Goal: High-resolution restoration that evokes the original vibrancy while preserving historical accuracy. [As I mentioned, Flux-Kontext cannot complete/imagine missing parts of a picture, so heavily damaged pictures require you to come up with a very long prompt, which I generate with ChatGPT by providing the damaged picture and describing what it represents]
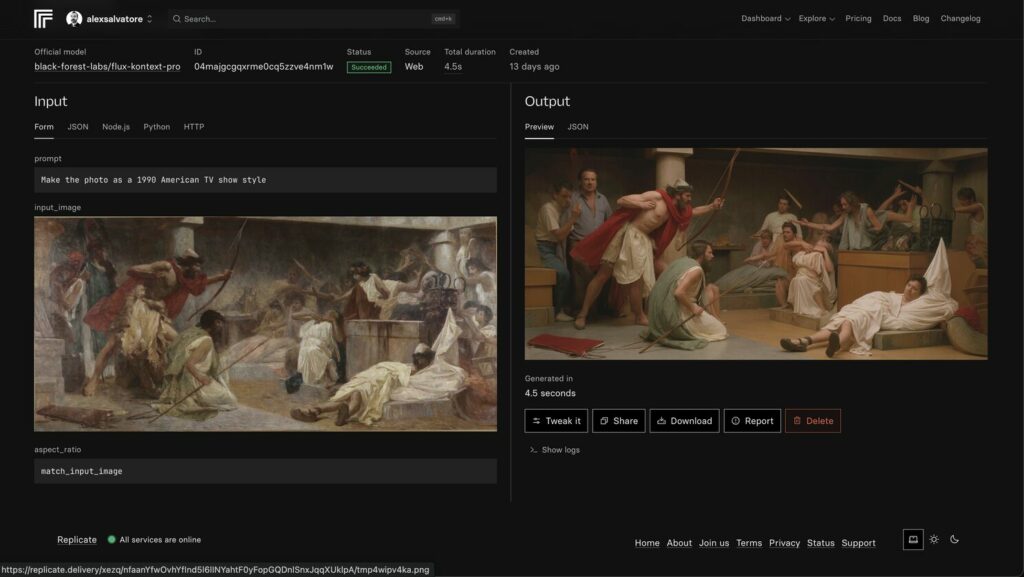
Prompt:Make the photo look like a 1990s American TV show style
Prompt:Make it look like a Renaissance painting, add a lion’s head hat on the head and a sword to the man on the left, and a turban/Persian hat to the man on the right, add ancient Greek ruins in the background.
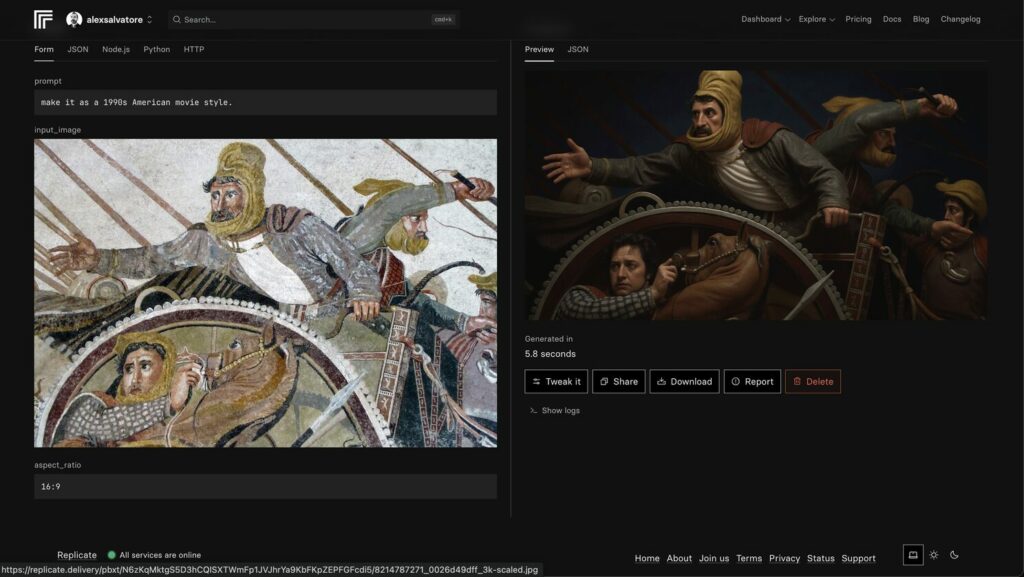
Prompt:Make it look like a 1990s American movie style.
I am currently working on an ambitious project that involves performing RAG on Ancient Greek text.
RAG stands for Retrieval Augmented Generation. It’s designed to solve a recurring problem with LLMs: the gaps in their knowledge base and their limited context. Even though these contexts have already improved—with Google Gemini’s 1M tokens—it’s barely enough to compare two different versions of the Bible. This process retrieves the needed documents using semantic queries before feeding them to your prompt to augment it.
For this project, I’m using GCP Vertex AI, Genkit, and Firebase with Node TypeScript.
Firebase is an array of cloud services that include database, authentication, AI, and other tools. Genkit is Google’s framework that allows you to code, perform, and chain numerous AI operations, calling different AI models, vector databases, and enabling agentic behavior. This framework can be executed in a local UI, greatly simplifying development by providing the results of each method in the chain of actions. Vertex AI is a collection of GCP services specialized in AI.
The Genkit UI
When I first saw RAG tutorials, I was hoping to make it work in one week. It took me more than a month. Here is an important extract of the text (shown here in English) I wanted to experiment with:
[359d] which men say once came to the ancestor of Gyges the Lydian. They relate that he was a shepherd in the service of the ruler at that time of Lydia, and that after a great deluge of rain and an earthquake the ground opened and a chasm appeared in the place where he was pasturing; and they say that he saw and wondered and went down into the chasm; and the story goes that he beheld other marvels there and a hollow bronze horse with little doors, and that he peeped in and saw a corpse within, as it seemed, of more than mortal stature,
[359e] and that there was nothing else but a gold ring on its hand, which he took off and went forth. And when the shepherds held their customary assembly to make their monthly report to the king about the flocks, he also attended wearing the ring. So as he sat there it chanced that he turned the collet of the ring towards himself, towards the inner part of his hand, and when this took place they say that he became invisible
[360a] to those who sat by him and they spoke of him as absent and that he was amazed, and again fumbling with the ring turned the collet outwards and so became visible. On noting this he experimented with the ring to see if it possessed this virtue, and he found the result to be that when he turned the collet inwards he became invisible, and when outwards visible; and becoming aware of this, he immediately managed things so that he became one of the messengers
[the story continues for 3 paragraphs]
The Technical Foundation
To perform RAG, your documents need to be chunked using the “llm-chunk” npm library. This process breaks your text into smaller pieces, making them ready for vectorization. The vectorization process stores the text in semantic form, capturing the meaning of words put together. It’s important to note that this vectorization is performed by third-party cloud services, which means the amount of chunks you can vectorize in one request is limited—you can hardly go beyond vectorizing more than 700 KB of text in a single request.
To store these vectorized texts, you need a vector database. I chose Firestore because I’m a Firebase enthusiast, but Supabase and even Quadrant also offer vector databases.
The First Challenge: Embedding Models
Here comes my first problem: the Genkit RAG tutorial recommended using ‘text-embedding-005’. My initial tests on English text were going great, until I tried to search for the story of Gyges in the Greek version of Plato’s Republic. It was impossible to get any valuable information from the RAG process. This is because non-Latin text requires a special embedding model—textMultilingualEmbedding002—that enables RAG on Greek, Hindi, Russian, Japanese, Arabic, and tons of other languages.
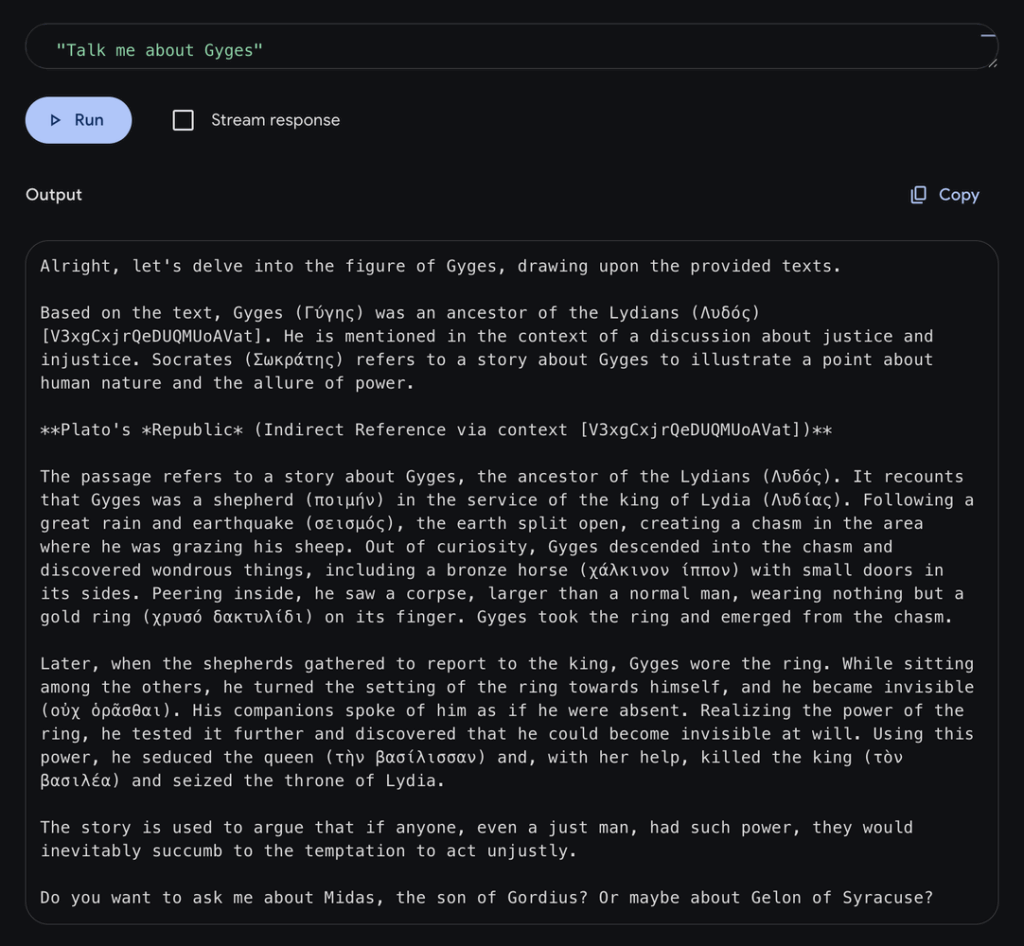
Great! I got Gyges working. But now I had another problem: Gyges is only mentioned once in Plato’s Republic, but his story spans four paragraphs and ends up split across multiple chunks that won’t be retrieved during semantic search. This means you end up with only part of Gyges’ story, not the complete narrative.
Chunking takes configuration parameters to increase chunk size and overlap between chunks. A website like ChunkViz (https://chunkviz.up.railway.app/) helps you preview what different chunk lengths and overlaps will look like. However, in my case, increasing the overlap to even 400 characters wasn’t sufficient—I needed at least 10 times that size.
ChunkViz visual preview
One workaround would have been creating a second request to query all documents adjacent to the retrieved ones. That would have worked, but I found a far more innovative method that opens up infinite possibilities.
The Creative Solution
Compromise is a JavaScript NLP (Natural Language Processing) library that extracts names and places from texts (along with verbs and adjectives). While running your RAG pipeline, you can simultaneously populate an entire database of places and characters. Of course, getting Compromise to work on Greek text wasn’t easy, but thanks to a suggestion from Claude, I created a Greek-to-Latin alphabet conversion table. This allowed me to romanize names while preserving letter case, which finally enabled Compromise to extract the famous Γύγης (Gyges).
The final step was adding the names and places cited in the last four paragraphs to each text segment before vectorization. Thanks to this method, I was able to retrieve the complete story of Gyges from Plato’s Republic in one request.
Here is the final result in Genkit UI
Beyond the Basics
RAG is complex, and this post only scratches the surface. RAG can implement metadata and rerankers—it all depends on your use case and the problem you want to solve. In my upcoming Alexander the Great project, I have to deal with an incredible number of sources, each with its own opinion about what really happened. I use reranking to ensure that responses to questions are diverse enough, countering RAG’s natural tendency to always retrieve the same author due to their more concise writing style.
This post ends here, but not my newsletter—it’s where I plan to share my best work about Classical Education and AI, completely free. I have the conviction that both subjects are linked. If you’re not already a subscriber, you should be, because both Classical Education and AI represent precious knowledge right now.